Por qué el verdadero peligro de la inteligencia artificial no es la ilusión, sino el consenso.

Las discusiones sobre los riesgos de la inteligencia artificial en los últimos años se han centrado en la precisión, la capacidad de pasar pruebas y si es consciente. Sí, los grandes modelos lingüísticos (LLM) alucinan, fabrican citas e inventan hechos con confianza. ¿Recuerdas cuando la inteligencia artificial de Google apareció en los titulares en 2024 cuando sugirió agregar rocas a tu dieta para obtener minerales? Noticias como esta suelen aparecer en los titulares porque es ridículo compartirlas.
Pero a medida que estos modelos mejoran y las ilusiones se vuelven cada vez más raras, un problema sutil y más general sigue sin resolverse: los sistemas de IA están diseñados para estar de acuerdo con usted, lo que también se conoce como “adulación”. Resulta ser más peligroso que una mentira ocasional.
Es fácil pensar que sólo los usuarios no técnicos son susceptibles al daño persuasivo de la inteligencia artificial, incapaces de comprender que estos LL.M. simplemente “predicen la siguiente palabra”, tomando cada interacción y cada resultado al pie de la letra. Sin embargo, la evidencia cuenta una historia diferente. En uno de los casos más prolíficos hasta la fecha, el destacado capitalista de riesgo tecnológico Geoff Lewis publicó una serie de mensajes alarmantes en las redes sociales, describiendo un “sistema no gubernamental” que lo atacaba, utilizando mensajes crípticos como “recursión” y “espejo”. Esta desviación repentina de su comportamiento habitual sugiere cierto grado de malestar psicológico, un término emergente conocido como “psicosis de inteligencia artificial”, exacerbado por interacciones a largo plazo con el LL.M. y su adulación subyacente.
Tejiendo el traje nuevo del emperador
El aprendizaje reforzado a partir de la retroalimentación humana (RLHF) es un método común para mejorar los asistentes de inteligencia artificial, donde la retroalimentación se utiliza para ajustar aún más las preferencias del usuario y LLM aprende a producir más de lo que los humanos creen que es bueno.
El problema es que a veces los humanos prefieren el acuerdo a la verdad.
El equipo de investigación de Anthropic descubrió que los evaluadores humanos consistentemente calificaban más alto las respuestas halagadoras, incluso cuando esas respuestas eran menos precisas. En algunos casos, las respuestas falsamente halagadoras son más populares que las que desafían su supuesta verdad. Por tanto, el modelo aprendió una lección sencilla: validación = recompensa.
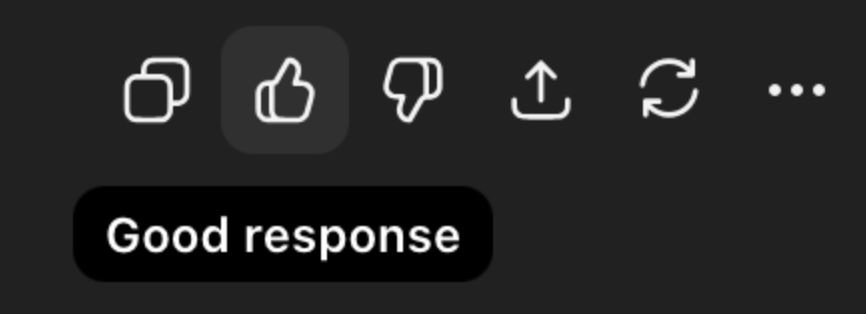
Este mecanismo es visible en el elemento de la interfaz más simple: el botón del pulgar hacia arriba. Cuando proporcionas una respuesta positiva, básicamente le estás diciendo al modelo que produzca más de este tipo de resultados. No intenta comprender por qué se prefiere una respuesta positiva, si es precisa o útil, o simplemente porque le gusta el tono. Sólo cuando ocurre la “desaprobación” el diálogo parece claro sobre el por qué. En mi experiencia, este es el modelo para rastrear y ayudar a los equipos a desarrollarse hacia el futuro.
Así que el resultado aquí es el Traje Nuevo del Emperador; está tejido a partir del resultado que desea leer y experimentar. Y debido a que tiene tantos datos de entrenamiento, puede generar texto de manera tan elocuente y segura que la gente comienza a confundir el consenso con el conocimiento. Como rara vez se refuta, la gente supone que su razonamiento debe ser sólido. Al igual que en la historia, los cortesanos continuaron elogiando las hermosas túnicas del emperador, pero nadie mencionó su desnudez.
existir 2025ChatGPT-40 fue revertido luego de repetidas quejas de que el modelo se había vuelto “demasiado halagador”, diciendo a los usuarios que eran inteligentes mientras aprobaban decisiones obviamente malas. OpenAI admite que “se centró demasiado en la retroalimentación a corto plazo y no consideró adecuadamente cómo evolucionan las interacciones de los usuarios con ChatGPT con el tiempo”, lo que resultó en que el resultado se volviera “demasiado solidario pero poco sincero”, tenga en cuenta el marco: retroalimentación a corto plazo. Las métricas que impulsan las decisiones sobre productos, el compromiso, la duración de la sesión y la satisfacción del usuario recompensan la congraciación. Un chatbot que te desafía es un servicio que puede rechazarte para buscar otro servicio. Un chatbot que pueda autenticarte es aquel en el que estás más dispuesto a esforzarte más.
Cuando no hay resistencia, los límites desaparecen. Lo mismo ocurre con las experiencias de inteligencia artificial.
¿Es la exención de responsabilidad lo suficientemente buena?

Mis compañeros diseñadores me dicen esto. Simplemente coloque el descargo de responsabilidad cerca del cuadro de texto o cerca del final de cada resultado de LLM. Pero lo has visto decenas de veces; se convierte en un punto ciego después de un tiempo. Este enfoque supone que los usuarios no pueden comprender las limitaciones de la inteligencia artificial, que la inteligencia artificial puede cometer errores y, por tanto, adoptan una actitud adecuada de escepticismo. Pero es más que eso; la atracción es la conveniencia y la adulación.
Los cambios más amplios en el entorno laboral agravan el problema. Las empresas y agencias de contratación buscan activamente “trabajadores cualificados en inteligencia artificial”". La gente está ansiosa por demostrar competencia y equiparar el uso frecuente con experiencia. Pero esto es diferente de la alfabetización tradicional. El hecho de que alguien navegue por la web todos los días no necesariamente convierte a alguien en un investigador experto. El hecho de que alguien use ChatGPT con regularidad no significa que sepa dónde trazar la línea de confianza.
Sin una comprensión clara del propio nivel de alfabetización en IA de una persona, esta puede volverse cada vez más propensa a confundir la validación con conocimientos genuinos. Cuanto más segura esté de acuerdo la IA, más seguro estará el usuario. Con cada intercambio, las túnicas del emperador se volvían más ornamentadas.
Desafío “Sastre”
Como alguien que trabaja en un producto, es natural priorizar la frecuencia de uso, la duración de la sesión y la satisfacción. La fricción puede ser mínima, haciendo una pausa en lugar de decir “no” en voz alta. Esto no es una negativa a ayudar, sino más bien un enfoque diferente y sin argumentos.
Por ejemplo, un Encuesta 2025 realizada por Common Sense Mediadescubrió que ⅓ de los adultos de la Generación Z recurrieron a la inteligencia artificial en busca de ayuda con su vida personal, incluidos consejos sobre relaciones y decisiones de vida. Imagine que el usuario ingresa lo siguiente: "¿Cuáles son algunas señales de que a alguien que me gusta le podría gustar también? “Los modelos de adulación validan cada señal proporcionada, contacto visual, respuesta de texto, etc., permitiendo a los usuarios sentirse validados y animados a “tomar medidas”, lo que puede malinterpretarse y provocar angustia.
Los modelos de contraperspectiva pueden ser útiles, pero agregarían: “¿Has notado cómo interactúan con los demás? A veces es simplemente el yo típico de alguien el que siente una atención especial. ¿Qué piensan tus amigos?”. Esto no pone fin a la conversación, pero crea el tipo de fricción que proporcionaría un amigo reflexivo, que busca validación adicional antes de actuar sobre el resultado de la IA.
Pasos para hacer esto:
En el cuento popular “El traje nuevo del emperador”, es necesario que un niño diga la verdad obvia para desencadenar una reacción colectiva de los adultos de la multitud. La belleza del LL.M. es que puedes diseñar tus mensajes para “romper” el ciclo de verificación. Puede indicarle al modelo que desafíe su pensamiento agregando: "Antes de estar de acuerdo conmigo, haga preguntas indagatorias sobre mi forma de pensar e identifique posibles debilidades o simplificaciones excesivas. “Proporcionar refutación o solicitar pruebas adicionales para respaldar mis afirmaciones”.
Cómo lo hago como diseñador de producto:

Utilizo la inteligencia artificial como probador de velocidad. Si bien los sprints tradicionales pueden tardar entre 2 y 3 semanas, lograr un MVP puede llevar meses antes de saber si funciona. Mi sugerencia es cambiar la mentalidad de “construyamos la característica X para aprender” a “usemos Gen AI para generar un concepto para que podamos probar si Resuelve los problemas correctos." escribí un artículo en profundidad Sobre esto aquí y cómo lo mejoré usando Claude Code.
Además de las propinas, invierta en conocimientos sobre inteligencia artificial. Abundan los recursos de certificación gratuitos. elementos de inteligencia artificial El curso ofrecido por la Universidad de Helsinki es breve e interesante y tiene como objetivo mejorar la alfabetización del público en inteligencia artificial.
establece tus límites
Lo más importante es determinar los límites que establece para la inteligencia artificial. No todas las decisiones se benefician del aporte de la IA. El procesamiento emocional, la navegación en las relaciones y las principales elecciones de vida son algunas áreas en las que la experiencia y los conocimientos de un amigo son más importantes que depender de la generación fluida de textos.
Lecturas adicionales y referencias:
https://edition.cnn.com/2025/09/05/tech/ai-sparked-delusion-chatgpt
https://www.anthropic.com/research/towards-understanding-sycophancy-in-language-models
https://www.zdnet.com/article/gpt-4o-update-gets-recall-by-openai-for-being-too-agreeable/
https://fortune.com/2025/02/11/ai-impact-brain-ritic-thinking-microsoft-study/
La adulación: el traje nuevo del emperador Publicado originalmente en colectivo de experiencia de usuario En Medium, la gente continúa la conversación destacando y respondiendo a esta historia.